

I contenuti duplicati sono uno dei più acerrimi nemici per chiunque si appresti ad ottimizzare un sito web. Rappresentano un problema serio che va affrontato se si vuole migliorare il posizionamento di un sito sui motori di ricerca. Ci sono diverse soluzioni per risolvere il problema. Le affronterò in questo articolo con un occhio di riguardo sulla soluzione da adottare quando su di un sito sono presenti migliaia di url duplicate: è il caso dei siti ecommerce.
Cosa sono i contenuti duplicati?
Chiarisco un concetto per i non addetti ai lavori: per contenuti duplicati non intendo che tu o chi per te abbia appositamente scritto lo stesso contenuto in diverse pagine, questo non si fa, ma credo tu lo sappia già. Però è come se davanti agli occhi di Google avvenisse questo, perché per motivi solitamente strutturali al sito, vengono a crearsi pagine con diverse URL ma con lo stesso contenuto. Google vedendo URL differenti non può che intenderle come pagine diverse, ma poiché quelle pagine riportano lo stesso contenuto di altre, ecco che vengono viste come contenuti duplicati.
Perché i contenuti duplicati sono un problema?
D’accordo dirai, si sono generate queste pagine ma perché sono un problema? La risposta è abbastanza semplice e si trova nella stessa domanda: sono un problema proprio perché si tratta di duplicati.
Prevenire il formarsi di contenuti duplicati
Ovviamente è possibile prevenire il crearsi di questa situazione ma innanzitutto per farlo devi essere tu a creare il sito. Se invece hai acquistato il sito da una piattaforma che vende siti con pacchetto tutto compreso, ti ritrovi il sito già bello e pronto e al massimo devi configurarlo. Probabilmente non sai nemmeno di avere contenuti duplicati sul tuo sito.
Come sapere se il sito ha contenuti duplicati?
Entra nel search console di Google -> Aspetto nella ricerca -> Miglioramenti HTML. Se il tuo sito presenta contenuti duplicati vedrai qualcosa di simile a questo:
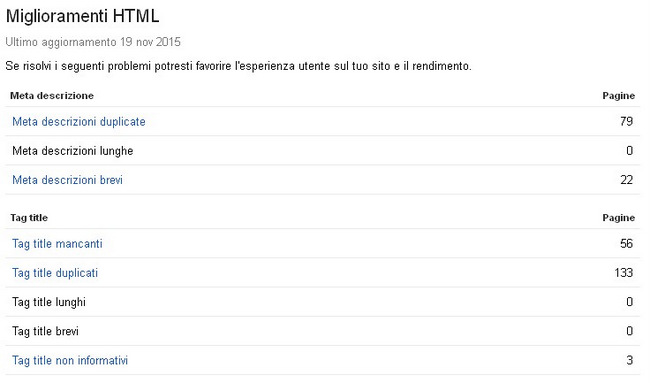
Come eliminare i contenuti duplicati?
Nonostante ci siano diverse soluzioni per eliminare i contenuti duplicati, ho letto spesso in articoli o nei commenti di esperti SEO che il rel canonical è la soluzione migliore rispetto alle altre. In realtà non esiste la soluzione migliore che va scelta caso per caso a seconda della situazione. In alcune casi alcune soluzioni sono addirittura impraticabili. Ecco che alla fine la soluzione migliore è solo quella che può fare al caso nostro. Ecco le possibili soluzioni da adottare per eliminare i contenuti duplicati:
- tag rel=canonical
- redirect 301
- disallow dal file robots.txt
- Utilizzo del Noindex
- parametri URL
Ma come ho scritto all’inizio voglio trovare la soluzione per una situazione estrema ma molto comune agli ecommerce, sopratutto se a realizzare questi siti sono stati altri e non ci viene nemmeno data la possibilità di agire sui codici.
Quindi partendo dal presupposto che abbiamo un sito ecommerce con URL dinamiche e migliaia di pagine duplicate, analizziamo una per una le diverse soluzioni, andando alla ricerca di quella migliore per la situazione esposta.
Attributo rel=canonical
Lo scopo del rel canonical è quello di creare una gerarchia fra le pagine. Inserendo una formula nell’head delle pagine secondarie, Google sarà in grado di capire che quella pagina è una copia della pagina principale (detta appunto canonica).
Ipotizziamo che questa sia la URL della pagina principale:
http://www.esempio.com/product.php~idx~~~373~~bikini-trasparenti~.html
e che questa sia invece quella della pagina secondaria:
http://www.esempio.com/product.php~idx~~~373~~variant~~~0~~bikini-trasparenti~.html
All’interno dell’head della pagina secondaria andrò ad inserire questa formula con la URL della pagina principale nel href:
<link rel=”canonical” href=”http://www.esempio.com/product.php~idx~~~373~~bikini-trasparenti~.html” />
Con il rel canonical ho escluso dalla vista di Google i duplicati e risolto il problema dei contenuti duplicati. Qualora te lo stessi chiedendo anche i link che dovessero puntare sulla pagina secondaria saranno attribuiti alla pagina principale. Nella pagina di supporto di Google è scritto: “Nota. Tentiamo di rispettare questa istruzione, ma non lo garantiamo sempre.“. Quest’affermazione però cozza su quanto solitamente leggo in giro nei forum da parte di molti SEO specialist, che ritengono quella del rel canonical come la soluzione migliore.
Può essere il rel canonical la soluzione migliore per il nostro caso?
Assolutamente no, perché devo agire ad una ad una su tutte le pagine duplicate, che essendo migliaia rendono questo un lavoro abnorme. Quand’anche tu fossi disponibile a farlo molto probabilmente non avresti accesso all’head.
Quando scegliere il rel canonical?
In ogni caso ti rimando a questa pagina di Google per un approfondimento sull’utilizzo di URL canonici.
Il Redirect 301
Il redirect 301 indica agli spider dei motori di ricerca che l’URL richiesta è stata trasferita in maniera permanente verso un nuovo indirizzo. Per questo motivo questo metodo, rispetto a quello precedente, è più sicuro. Presenta anche un altro vantaggio. La formula va inserita nel file .htaccess e non in tutte le pagine una ad una. Ci sono due versioni:
Redirect permanent /old.php http://www.miosito.com/new.php
oppure:
Redirect 301 /old.php http://www.miosito.com/new.php
Può essere il redirect 301 la soluzione migliore per il nostro caso?
Nonostante non dobbiamo entrare in ciascuna pagina, resta il problema che dobbiamo scrivere migliaia di URL, una per ogni pagina secondaria. Nel mio caso avevo da scrivere 5000 formule.
Quando scegliere il redirect 301?
Sul forum di Giorgio Tave è possibile approfondire l’argomento redirect 301.
Meta Robots: i tag NoIndex/Follow
Dobbiamo inserire il Meta tag Robots con gli attributi noindex/follow in ciascuna pagina cosi come di seguito:
<meta name=”robots” content=”noindex,follow” />
Il contenuto duplicato viene eliminato dal valore noindex, che indica al motore di ricerca di non indicizzare la pagina. Il valore follow invece consente alla link juice di passare attraverso la pagina duplicata.
Può essere il tag noindex/follow la soluzione migliore per il nostro caso?
Anche questo metodo è arduo da usare nel nostro caso perché dovrei inserire quella formula nell’head di ciascuna pagina. Un piccolo miglioramento rispetto alle formule precedenti è rappresentato dal fatto che non devo ricavarmi una formula per ciascuna pagina, perché la formula noindex/follow va bene per tutte.
Parametri URL
Nella mia ricerca della soluzione migliore, sono finito direi abbastanza casualmente (non l’ho mai trovato nell’elenco delle soluzioni possibili) nei parametri URL. Devo dire che è una soluzione molto interessante che viene in aiuto sopratutto a chi ha un tipo di URL dinamiche. Però va presa con molta cautela.
In pratica ci sono dei parametri che si ripetono nelle URL. Dovremo segnalare a Google uno o più di questi parametri chiedendogli di non seguirli. Ovviamente il parametro scelto non dovrà essere presente nella URL principale, altrimenti Google non seguirà nemmeno quella, ecco perché scrivevo di fare attenzione.
Possiamo visualizzare i parametri presenti nel nostro sito seguendo questo percorso nel Google Search Console > Scansione > Parametri url.
Vediamo che nel nostro sito abbiamo 8 parametri: idx, nocache, currency, locale, skip, rpp, go, link.
A questo punto dovremmo confrontare le nostre URL principali con quelle duplicate e dovremo cercare di capire quali sono i parametri che presenti solo in queste ultime e non nelle url principali. Ma come sempre è meglio farti vedere quello che voglio dire con un esempio:

Nel link principale troviamo il parametro idx. Nel secondo link troviamo i parametri nocache, idx, locale, currency. Nel terzo link ancora idx ma anche variant. Possiamo vedere che il parametro che soddisfa le nostre condizioni è il no cache. A questo punto selezioniamo modifica e rispondiamo NO alla domanda “Questo parametro cambia i contenuti della pagina visibili all’utente?“. Ora non ci resta che aspettare. Quanto? Non lo so e non è dato saperlo. Questa soluzione funziona? Purtroppo non lo so. Sarebbe utile per risolvere il problema di chi ha migliaia di URL duplicate e che non può accedere all’head delle pagine e nemmeno al file .htaccess. In ogni caso ti rimando a questa pagina di Google per un approfondimento sui parametri URL.
Questo metodo può essere molto efficace soprattutto se impareremo ad utilizzare i caratteri jolly per escludere determinati contenuti derivati da url duplicati che sovente derivano dall’identificazione di sessione o altre funzionalità simili; in tal caso infatti spesso l’url contiene dei caratteri speciali come dei ? al suo interno, vi faccio un esempio:
Disallow dal file robots.txt
Questo metodo viene utilizzato per impedire ai bot di accedere ad alcune parti del sito che non vogliamo siano indicizzate. Solitamente lo si usa per impedire al motore di ricerca di indicizzare:
- documenti privati
- pagine incomplete
- versioni pdf o stampabili delle pagine.
Si tratta quindi di un metodo drastico e molto efficace che possiamo utilizzare anche per eliminare i contenuti duplicati. Con il disallow nel file robots.txt, il file non verrà più scansionato e sarà quindi deindicizzato: per il motore di ricerca quella pagina non esisterà più. Tanto è vero che se la pagina eliminata riceve dei link esterni, la loro efficacia sarà nulla, non potendo nemmeno essere trasferita su un’altra pagina, come avviene per esempio con il redirect 301. Prima di procedere con il disallow, effettuate un controllo. Se la pagina che volete eliminare dovesse ricevere link esterni, chiedete di sostituire il link con quello della pagina principale.
Caratteri jolly
Le url duplicate contengono al loro interno dei caratteri speciali come per esempio il punto interrogativo “?” (ma ce ne sono altri comuni) chiamati caratteri jolly. Escludendo questi caratteri dal disallow nel file robots.txt, avremo detto a Google di non considerare le pagine che li contengono. Può essere il caso che si viene a creare quando, un visitatore del nostro sito, cerca un argomento tramite apposita funzione di ricerca. Si viene a creare una url tipo questa:
http://www.miosito.com/?s=parolaricercata
In questo caso possiamo impedire che le url derivanti da una ricerca siano indicizzate, identificando il carattere jolly (in questo caso “S”) e inserendo questa formula nel file robots.txt:
User-agent: *
Disallow: / s =
L’asterisco (*) è un carattere jolly. Il suo uso in questo caso sta a significare che le direttive sono per tutti i robot e non per uno in particolare (per esempio per il solo Googlebot).
Utilizzo di disallow
Chiarito che con il disallow dal file robots.txt possiamo indicare al bot cosa escludere, vediamo alcuni esempi pratici del suo utilizzo:
Escludere una cartella e le sue sottodirectory
Con questa regola specifichiamo che “/miacartella/” e tutte le sottodirectory sono da escludere:
| User‐agent: * Disallow: /miacartella/ |
Escludere in file che inizia per …..:
Con questa regola indichiamo al bot di non accedere a qualsiasi file che inizi con “miacartella”
| User‐agent: * Disallow: /miacartella |
Escludere un solo tipo di bot:
Questa regola è rivolta al solo “googlebot” intimandogli di non accedere a qualsiasi file che inizi con “miacartella”
| User‐agent: googlebot Disallow: /miacartella |
Regola allow
Nel caso volessi escludere una cartella tranne un file posso utilizzare la regola allow, come puoi vedere di seguito:
| User‐agent: * Disallow: /miacartella/ Allow: /miacartella/page.php |
Carattere jolly
Oltre a consentire che una direttiva sia da applicare a tutti i tipi di bot, l’asterisco (*) consente di indicare più caratteri in una istruzione
Faccio subito un esempio chiarificatore: dall’accesso a qualsiasi URL contenente “page”
| User‐agent: * Disallow: /*pagina |
Con questa direttiva ad ogni bot è chiesto di escludere qualsiasi URL contenente “pagina”.
Per esempio sarebbero escluse dai bot:
- bellezza-paginaspeciale.php
- /miacartella/pagina-esempio.php
- /pagina/ (compresi file e sottocartelle di questa directory)
Formula per risolvere il nostro caso:
L’abbiamo trovata. Quella dell’ultimo esempio è anche la direttiva che ho utilizzato per risolvere il problema delle url duplicate nel nostro caso specifico:
| User‐agent: googlebot Disallow: /*? Disallow: /*variant |
L’abbiamo trovata. Quella dell’ultimo esempio è anche la direttiva che ho utilizzato per risolvere il problema delle url duplicate nel nostro caso specifico:
Quale di queste è la soluzione migliore?
Vi capiterà molte volte di leggere che il canonical è la soluzione migliore, a seguire il redirect 301 anche se nasce concettualmente per un altro scopo. Poche chance di successo vengono concesse ai parametri URL. Ma rel canonical ha bisogno di una condizione precisa: devi poter accedere all’head. Tutti quelli che hanno acquistato il sito da una di quelle piattaforme tutto compreso, sanno benissimo che questo non è possibile. Quindi che fare? Ti diranno di provare con il redirect 301. D’accordo ma per far questo devi avere accesso al file htaccess. Anche questo ti è precluso. Probabilmente però contattando la piattaforma ti potrebbero dire “prepara le formule e passacele, provvederemo noi ad inserirle”. Bene problema risolto dirai, Devo solo prendermi la briga di recuperare tutte le URL, scrivere le formule del 301 per ciascuna di esse e poi passarle per l’inserimento. Ma se (come nel caso di un ecommerce multilingua) ti trovassi a dover scrivere 5000 formule? E’ questa la situazione in cui mi sono ritrovato anch’io e sinceramente la cosa non è che mi andasse tanto a genio. Quando mi pareva l’unica soluzione possibile l’ho accettata con entusiasmo e inizialmente il peso mi sembrava un problema che avrei superato alla grande. Ma dopo aver recuperato tutte le URL con XENU, e aver scritto circa 200 formule mi sono fermato. L’impresa era titanica. Davvero non c’era altra soluzione?
Cosi ho ripreso la mia ricerca, questa volta ancora più approfondita.
Soluzione per sito con migliaia di contenuti duplicati
E’ questa la situazione che mi sono trovato ad affrontare: sito ecommerce costruito su una piattaforma tutto compreso, con url dinamiche e appunto migliaia di contenuti duplicati. Il fatto che il sito fosse anche multilingua ha aggravato la situazione, perché le pagine di ciascuna lingua avevano altre 2 pagine duplicate: totale 5000 pagine duplicate!